
一些平常没怎么使用过的正则技艺;
作为一名JSer,基本的正则技术是必备的,但是最近在网上看到这么一段字符串相邻去重代码:
1 | function uniqueAdjacent(str) { |
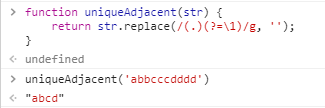
当时我的第一反应是,嗯…秀…这好像是我正则知识树遗漏的区域,然后开始填坑之旅~
零宽断言
零宽:可以理解为正则匹配的时候会匹配一个位置,但是它没有宽度;
断言:判断断言之前或之后应该有什么或没有什么;
零宽肯定先行断言
这里的肯定是指判断是否有什么,先行(lookahead)指的是向前看,断言的这个位置是为前面规则服务的。语法就是前文中的?=,举个例子:
1 | 'CoffeeScript JavaScript javascript'.match(/\b\w{4}(?=Script\b)/); |
上述正则会匹配4个字母,并且这4个字母后紧跟Script,同时它前后具有单词边界;此处的零宽规则虽然参与了匹配,但是提取的文本是不包含零宽规则匹配的内容的,所以我们称其为”零宽”。
1 | 'CoffeeScript JavaScript javascript'.match(/\b\w{4}(?=Script\b)\w+/); |
该例中,我们发现\w+依旧能够匹配Script,最后提取的内容是JavaScript,这说明(?=Script\b)在给前面正则表达式提供规则服务的同时,不会影响到后面的匹配规则;
零宽肯定后行断言
有前自然有后,后行断言(lookbehind)向后看,使用?<=的语法,所以它是放在匹配语句的前面,筛选出断言外的内容:
1 | '演员高圆圆 将军霍去病 演员霍思燕'.match(/(?<=演员)霍.+?(?=\s|$)/); |
零宽否定先行断言
否定语法?!,用于筛选不在规则内的信息:
1 | 'TypeScript Perl JavaScript'.match(/\b\w{4}(?!Script\b)/); |
零宽否定后行断言
否定语法?<!,用于筛选不在规则内的信息:
1 | '演员高圆圆 将军霍去病 演员霍思燕'.match(/(?<!演员)霍\S+/); |
正则内捕获
反向引用
反向引用就是通过\数字形式来匹配正则表达式中前面圆括号捕获的内容,我们以一个匹配任意标签的正则为例:
1 | '<App>hello regex</App>'.match(/<([a-zA-Z]+)>.*<\/\1>/); |
可以看到\1会匹配第一个标签正则匹配的内容,\n就是匹配第n个括号内的表达式,如果存在嵌套情景,则会逐层对应嵌套内的表达式匹配内容,如下例:
1 | '<App>hello regex</App><p>A</p><p>hello regex</p>'.match(/<((A|a)pp)>(hello regex)+<\/\1><p>\2<\/p><p>\3<\/p>/); |
在ES2018中,我们前面所说的反向引用,不仅可以使用\数字的方式匹配,还能够自定义标签来匹配,使用语法是在括号匹配的最前面添加?<key>,key只是示意,你可以自行命名,然后使用k<key>就可以引用前面匹配的内容(注意有个k):
1 | '<App>hello regex</App>'.match(/<(?<tag>[a-zA-Z]+)>.*<\/\k<tag>>/); |
正则外捕获
正则外捕获与正则内捕获的差异在于我们通过RegExp构造函数的实例属性$number来匹配我们括号内的内容:
1 | '@abc'.match(/@(ab)(c)/); |
其实在替换场景中使用度比较高,比如我们为了提高信息安全,隐藏手机号的中间4位:
1 | function formatPrivacyPhone(phoneNum) { |
小结
现在回头再看看文章开头的操作,哦,不就是零宽先行断言加反向引用的组合么,(.)捕获组内匹配除换行符\n外的任意单字符,然后先行断言内引用前面匹配的字符,等价于在字符串中找到2个相同的字符,然后将前面的字符替换为空,最终得到一个相邻字符不重复的字符;注释掉的方法就是将匹配的多个相邻字符以一个替代掉。嗯,就是这么简单。