一篇分享文…
背景
由Vue的H5页面开发转为React-Native的原生应用开发;
不是所有成员过去都是主React技术栈,使用方式和理解各有不同;
这篇文章是本人过去对React的使用的一些思考和总结,希望能让还不熟练的成员对该框架中的一些易出错点在未来遇到时进行规避,同时尽量能够统一一些逻辑组织和写法,减少多人合作时因不同风格带来的理解成本;
框架对比
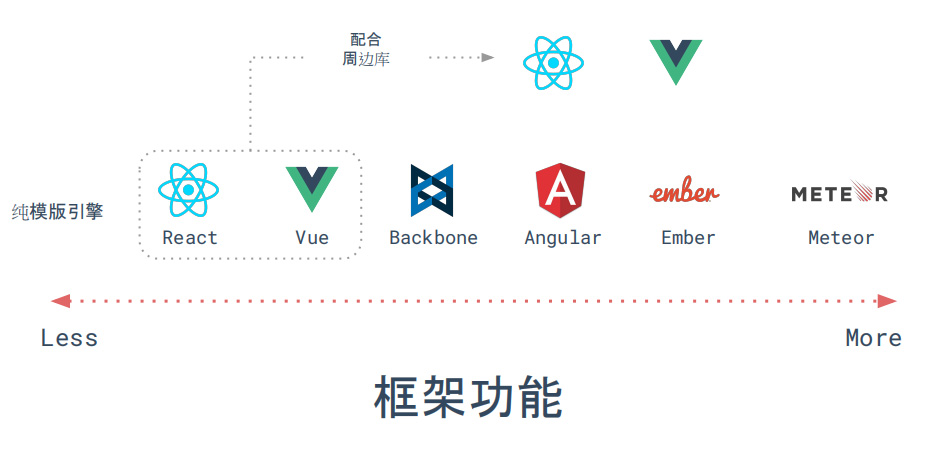
上图来源于尤大之前在平安做的分享的PPT,可以看出Vue和React两者在框架方面都是比较轻的(React本身其实只是一个视图库,而Vue尤大本人称其为渐进式框架),它们在复杂应用中都需要一些配套的库参与才能构成一个完整项目。
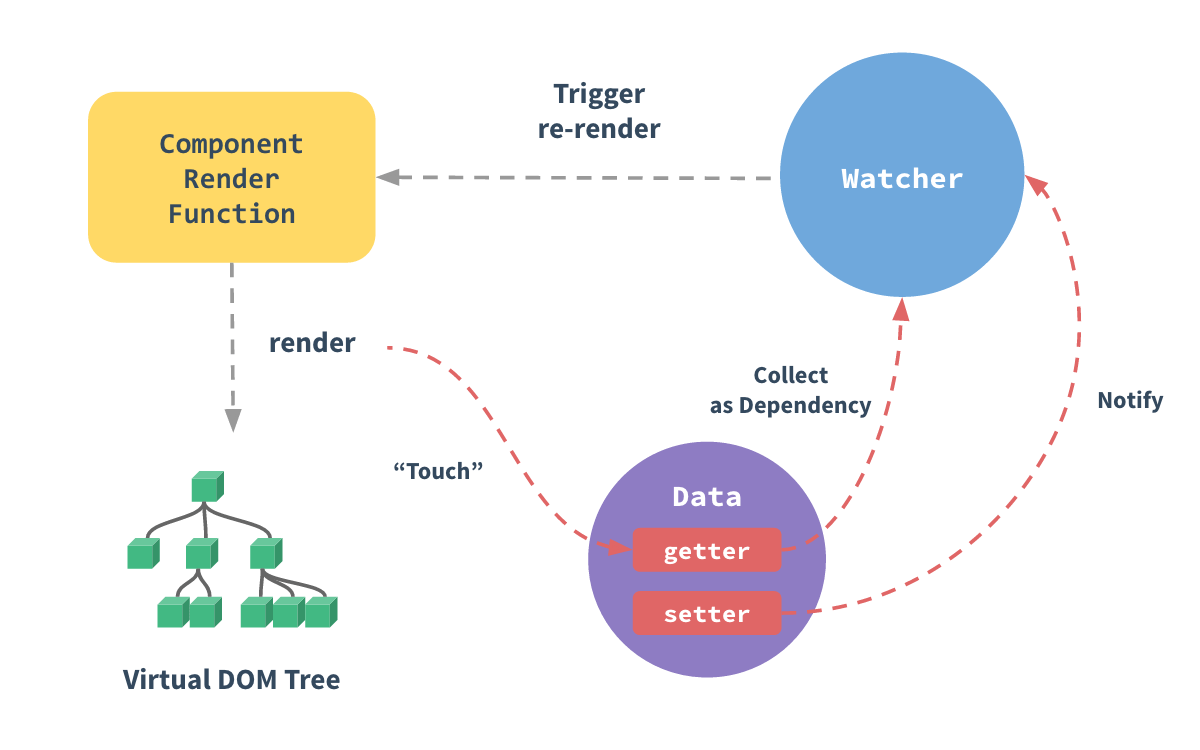
在实际使用上,借助于JSX的特性,我们可以更像编写原生JS一样去敲React,而Vue则内部集成了一系列的指令(v-if逻辑判断、v-bind负责绑定数据、属性表达式等、v-for循环结构、v-on事件监听、v-model负责表单域中的双向绑定、v-showCSS样式显示切换总是渲染)和数据收集机制来使我们同样轻松直接地进行逻辑编写;在数据同步上,React需要手动地进行setState,而Vue由于内部代理的机制(过去的Object.defineProperty到Proxy代理)我们无需关注具体更新操作,使用提供的指令即可;另外在大型项目中比较重要的状态管理问题我们会在后文讨论。
Vue的响应式(追踪变化):
React开发注意点
命名要求
React组件声明时,第一个字母须大写;
React中的事件、属性命名须遵守驼峰规范,如className、onClick等等;
setState问题
这里我只讲表现形式,底层原理有时间各位可以自行研究~
合并更新问题,当我们在一个函数内进行多次
setState时,存在覆盖性对同一属性进行多次setState,取最后一次执行和合成性多次setState动作会合并成一次。注意PureComponent使用下可能带来的问题,由于
PureComponent实现了浅层拷贝版本的ShouldComponentUpdate,当我们进行引用类型的setState时,当前组件不会产生更新(相同引用地址return true)。而当我们使用PureComponent时往往是为了带来一些性能优化的(避免父组件发生render,子组件props未改变却也造成了额外的rerender),所以须要我们注意潜在的认知bug。
1 | // PureComponent下 |
处理方式:对于对象通常可以采用Object.assign({}, this.state.xxx)、{...this.state.xxx}的方式、数组则可以使用解构或拼接重新赋值[...this.state.xxx],[].concat()的方式。
- 同步还是异步,如何同步获取更新后的数据,
setState由于其底层的判断执行机制,会给我们一种“异步”的感觉,但本质上它还是同步实现的。在我们的生命周期及合成事件中表现为异步,在原生事件(addEventListener)及setTimeout中表现为同步(为什么这类情况下不是异步表现,可以简单理解为Event Loop下的机制React无法介入修改,而生命周期和合成事件相关都是React自身定义并规定执行流程的)。
我们经常会遇到一种场景是先对state内的数据进行更新(如fetch我们的数据然后在组件中保持状态),再对该数据操作。假如我们按下面的操作肯定是不行的,拿到的还是初始状态值:
1 | // state.number 0 |
如果要同步顺序地获取修改后的状态,官方提供了回调的方式如下:
1 | this.setState({ |
setState第一个参数也支持传递一个函数进去,该函数的参数为要操作的state,我们可能会在一些频繁对state变量操作的场景遇见:
1 | this.setState(prevState => { |
最后还有一些不推荐的做法,如setTimeout:
1 | setTimeout(() => { |
合成事件与函数绑定问题
先说合成事件(SyntheticEvent),对Web应用来说,存在很多不同浏览器的兼容问题,过去需要我们根据不同环境做兼容处理,而现在React内已经帮我们做好了统一的封装,所以在React中的一些如onClick触发的回调已经不是我们原生的点击事件了。就拿事件冒泡来说,过去我们可以直接return false阻断继续冒泡,但是从v0.14版本开始就无效了,须要严格执行e.stopPropagation()或者e.preventDefault()。原生的绑定即前文提到的addEventListener。
再说函数绑定问题,先看如下几种绑定方式:
1 | export default class Demo extends PureComponent { |
先说绑定一、二,两者都是推荐的做法,目的都是拿this,个人倾向于使用第二种箭头绑定的方式,原因是绑定一每个都要去构造函数内手动bind一次,麻烦…绑定三能不用就不用,原因是直接写在render方法中的箭头匿名函数每一次重新渲染都是不一样的,这样造成的结果也很明显:diff算法会判定其发生变化对其再更新,带来额外的性能消耗。
另外,其实在类中直接声明一个箭头函数是不行的,会报下图问题:
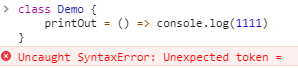
事实上,我们能够通过该方式声明是依赖了babel的@babel/plugin-proposal-class-properties插件。通过该插件上图中的内容会被转化为:
1 | var Demo = function Demo() { |
以上是在{ "loose": true }配置下的转化,默认情况配置是false,会采用Object.defineProperty的方式。具体详情可见babel官方。
React事件系统的冒泡捕获
React的合成事件其实是统一冒泡到document上,再通过dispatchEvent进行处理的。当我们进行一些DOM事件绑定时,应当尽可能地使用合成事件处理,避免原生绑定和合成事件绑定混用,可以看下面的输出例子:
1 | componentDidMount() { |
当我们点击test时,最终依次输出结果:
- dom child
- dom parent
- react child
- react parent
- document
生命周期
React的生命周期要分版本看,目前我们的项目版本是v16.8.x,以下对比v16.3前的周期和v16.3后的周期:

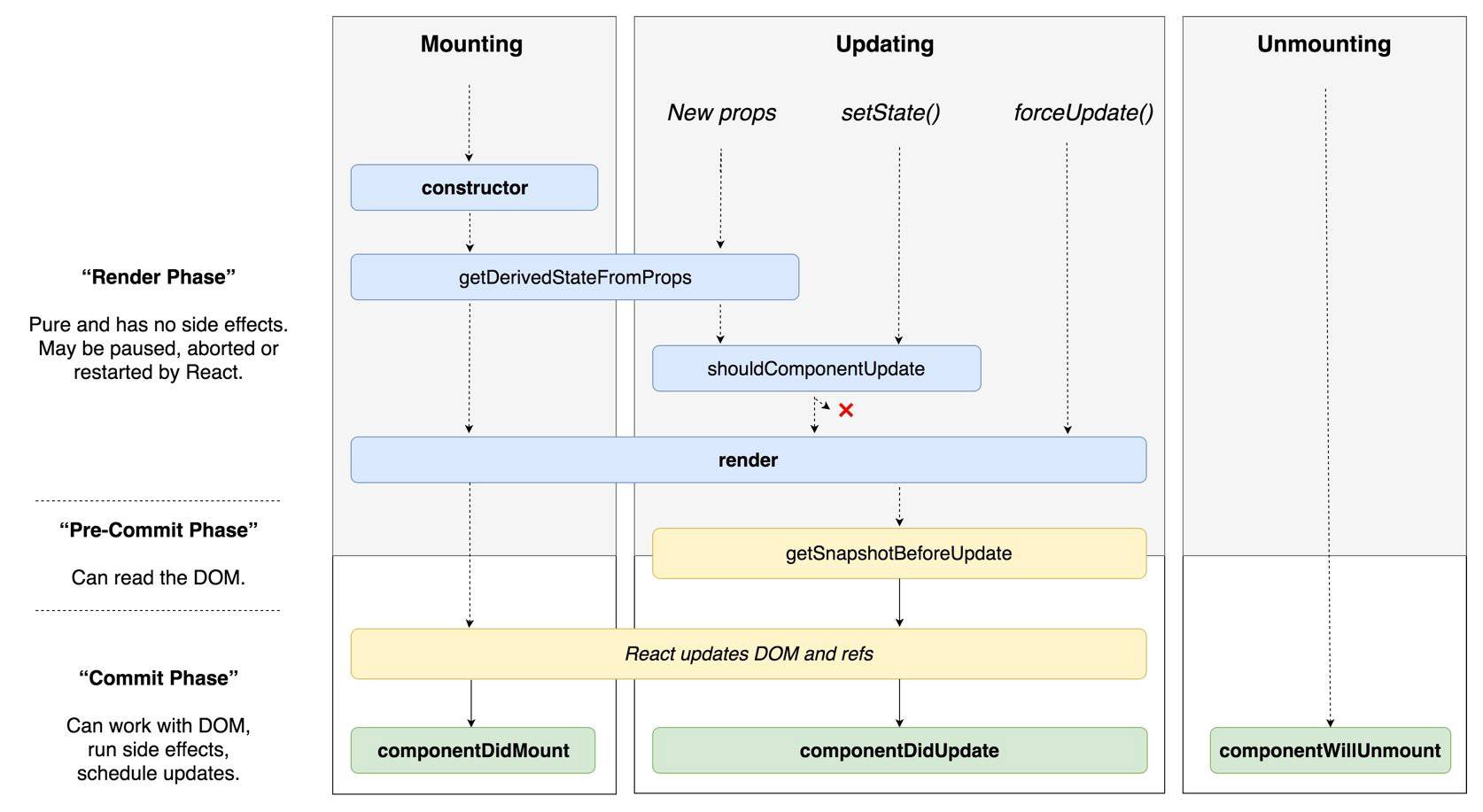
对比看来,在未来新版本中有意移除以下周期函数(目前可以使用UNSAFE前缀进行标记来提示自己未来某个时间节点或许会被移除):
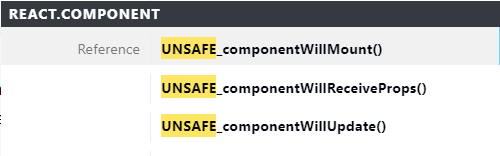
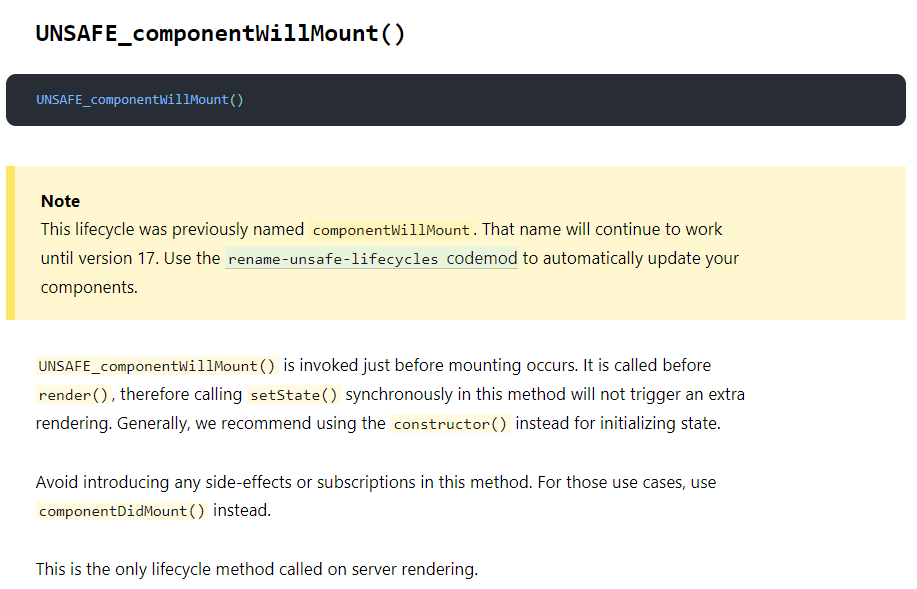
原因在于React在v16版本中采用了新的异步Fiber架构,这种架构下,React的渲染是切片式的,有点像计算机系统中的任务调度,它会将渲染分为两个阶段:render和commit。在render阶段,如果遇到紧急任务,会将之前做的事情全部舍弃,优先执行,然后再重新执行之前的任务。这也是为什么不要在componentWillMount中进行AJAX请求的原因(可能会因为一些奇奇怪怪的原因触发多次)。另外,如果在SSR时,componentWillMount中的数据请求会被执行两次(客户端、服务端各一次)。
官方也建议在constructor内初始化state,而不要在componentWillMount内setState:
服务端请求、一些事件订阅也应当放在componentDidMount中执行,订阅类须在componentWillUnmount中取消订阅:
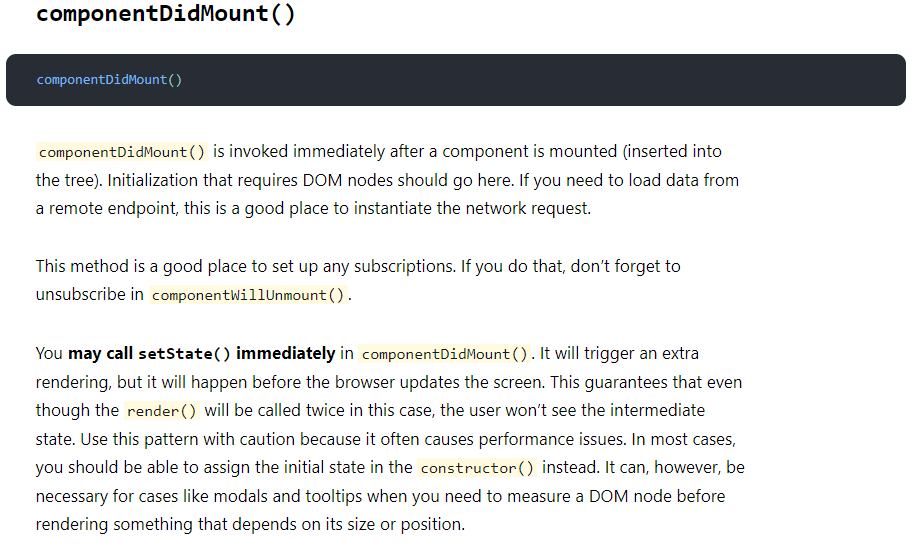
你或许会对获取请求数据后在componentDidmount中setState触发额外的render抱有疑惑,我当年也有,不过上图也给出了解答:额外的render会在浏览器更新屏幕前进行触发,所以即便有多次render用户也不会感知。
getDerivedStateFromProps
这个静态方法是在v16.3时出现的,目的其实就是为了渐进废弃之前render前的一些Cycle:
- componentWillReceiveProps
- componentWillMount
- componentWillUpdate
那为什么要干掉这些Cycle呢?因为过去有太多人会在这些周期里做一些带有副作用的事情,比如典型的发AJAX请求等等。
需要注意的是,在16.3版本这个生命周期只有在父组件重新渲染时,当前子组件才会被连带触发,而子组件本身setState则不会触发。另外从16.4版本开始已经兼容成了setState和forceUpdate都会触发。
1 | class ExampleComponent extends React.Component { |
改动Reason参见官方RFC。
getSnapshotBeforeUpdate
在16.3版本中还引入了一个新的生命周期getSnapshotBeforeUpdate,其实这玩意我们基本没啥用到的场景,其功能就是在下一次更新DOM前提供了一个介入操作数据(snapshot)的时机。
1 | getSnapshotBeforeUpdate(prevProps, prevState) { |
受控与非受控组件
可以简单理解为表单域的值是否受state控制。
冷门API
冷门但不代表没用,下面提几个:
- forceUpdate
- createPortal
- Children
- cloneElement
forceUpdate
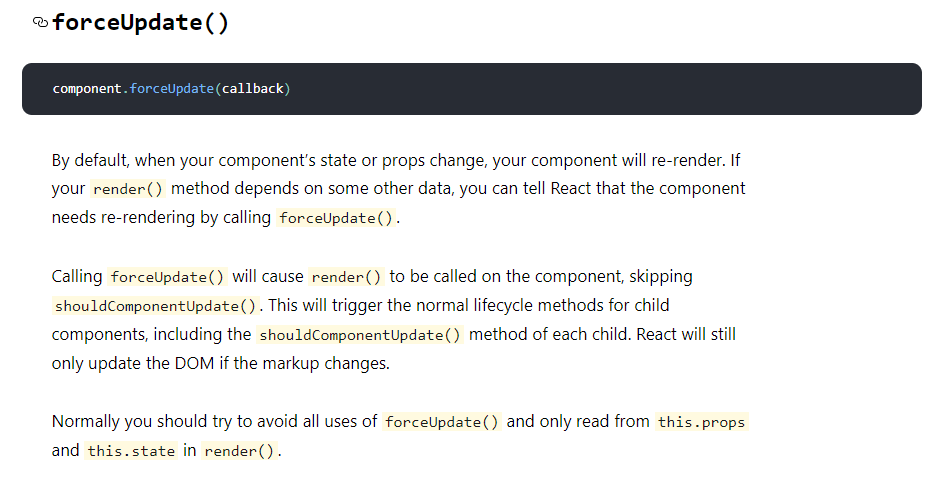
forceUpdate通常在我们不依赖组件本身state进行更新时触发,即我们开发者本身确认一些别的属性变化须要强制触发组件进行更新时使用。这种方法会直接跳过当前组件的SCU,但不会影响子组件的正常SCU。
PS:大多数场景我们不需要这个API,根据props、state控制即可。
createPortal
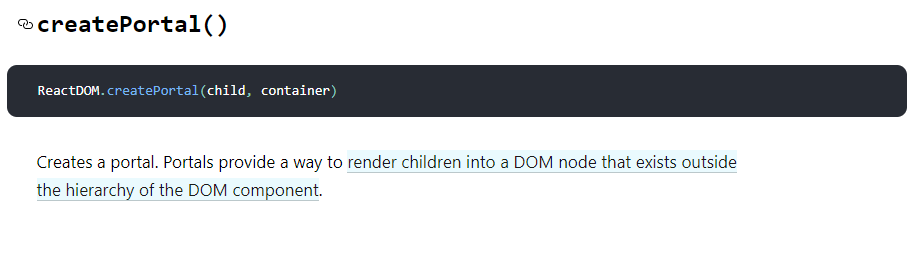
相当于提供我们一个方法直接在指定的DOM结构下配置,常见的应用场景就是全局模态框:
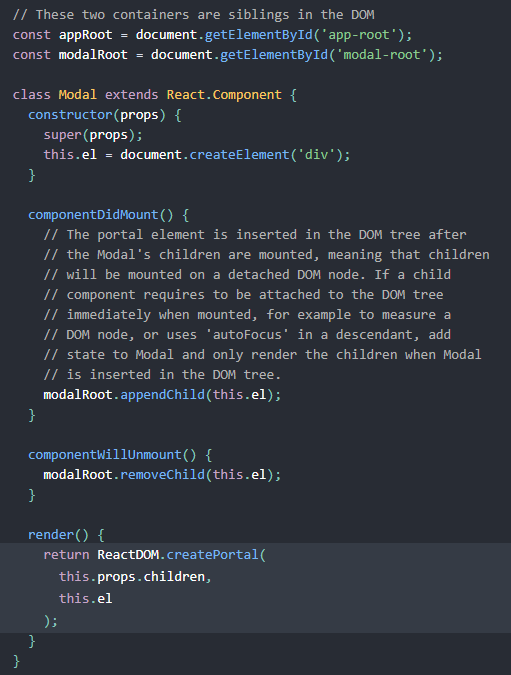
BTW,由于依赖ReactDOM,对于我们RN的场景是无法应用的。
Children
我们都知道在props对象中还有children这个属性。它能够从某种程度上减少我们在一个组件内的嵌套层级,就是props.children对于我们开发者来说就是一个黑盒,我们对它可能传入的数据结构是不可知的(表达式、布尔、render function等等),如果我们没有对其进行操作,那其实没什么所谓。但只要我们对其进行操作了,比如下意识以为是个数组进行props.children.map这样的调用就要注意,非Array就直接报TypeError了。那怎么处理类似这样的情景呢?
其实React.Children恰好就是为我们提供处理props.children数据结构能力的API,其具有的方法如下:
- map
- forEach
- count
- only
- toArray
React.Children.map
1 | React.Children.map(props.children, child => {}) |
这个API接收两个参数,第一个就是我们通常要处理的黑盒prop.children,第二个入参回调,其实就是我们遍历的元素上下文,通过它,我们能够进行定制化的操作。
并且根据源码,当props.children为null和undefined时,最终会原值返回,其余情景则是返回一个数组。
React.Children.forEach
跟React.Children.map类似,都是迭代操作,只不过这个不会返回数组。undefined和null时的判断逻辑同上。
React.Children.count
返回其中内部元素数,其值与前面两个迭代方法的回调触发次数相等。
React.Children.only
用于判断传入的children是否只有一个child。注意接收类型是React element。不能拿React.Children.map()返回的结果再去判断是几个child,因为此时你拿到的已然是一个Array类型。
cloneElement
前文中我们通过React.Children的类方法得到了访问本是黑盒的props.children的能力。React.cloneElement则是能让我们在操作React element时,进行浅层的新props merge,传入的新children则会替换旧的children。原element的key和ref都会保留。
先看一下API定义:
1 | React.cloneElement( |
由于是拷贝返回一个新的组合元素,React.cloneElement处理element时可以大致理解成<element.type {...element.props} {...props}>{children}</element.type>。
对于一些有公共方法或属性须要传递的组件,我们能够提前将其需要的信息配置进去。举个例子。
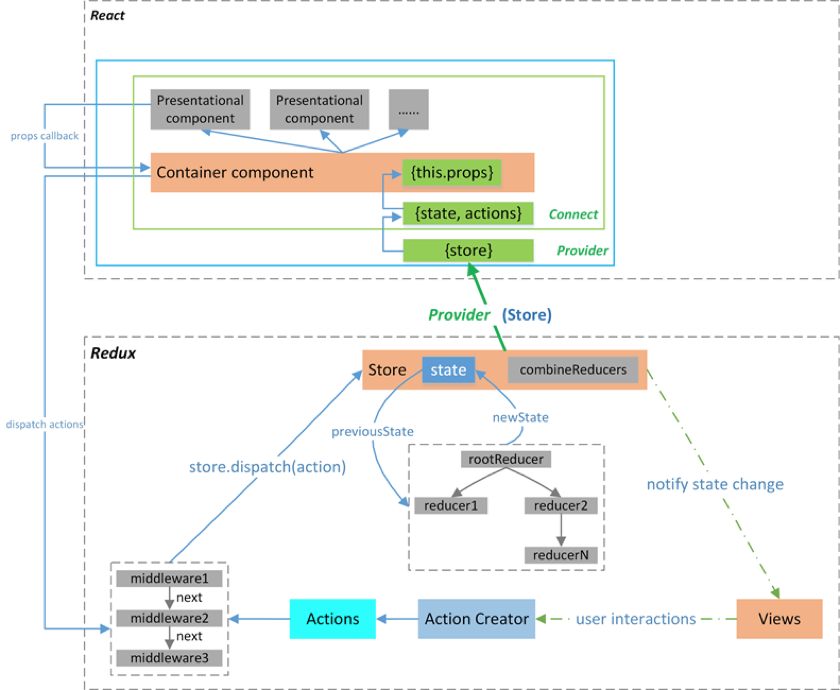
数据管理
React的数据管理也是一个逐步演化、进步的过程:单向数据流方面,从flux到redux,再到社区一系列的成熟中间件thunk、saga、observable等辅助;观察者方面,有类似Vuex的mobx。
Redux
讲Redux前,简要提提Flux(主要是本人没用过)。Flux作为数据单项流的先驱,本身其实仅是一种设计模式(跟React一样,由FB提出),即便是源码中也主要是对dispatcher的实现。它的出现是为了解决MVC混乱的数据流向问题。对于Flux来说,视图层唯一的数据源都是来自store,通过dispatch action去进行数据拉取和更新(event监听)。
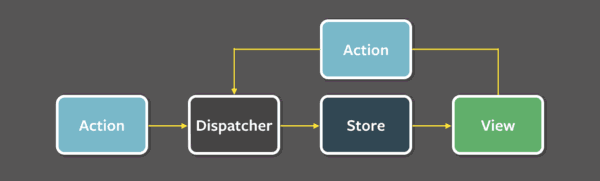
既然是一种思想,那就意味着不同的开发者会有各种实现和理解,无法统一在某些场景的处理方案。外加其中存在很多冗余代码,于是乎有了后续在社区中脱颖而出的Redux。
Redux同样是类Flux设计,它简化了Flux的一些冗余代码,其本质上就是一个叫redux的npm包,内置了不少API让我们建立store,构建action、组织reducer等。当然完整的数据管理,光有redux库是不够的,如果把store理解为数据库,那我们需要一个东西将数据与我们的React应用连接起来,那就是react-redux,它是由Redux官方提供的React绑定,可以放心食用。
先聊聊几个redux的核心API:createStore、combineReducers、applyMiddleware、compose、bindActionCreators。
createStore
通过阅读源码,可以知道createStore接收三个参数,最终返回一个对象,其中有如dispatch、getState等关键状态改变获取的方法:
1 | function createStore(reducer, preloadedState, enhancer) { |
接着我们一个个分析参数,第一个参数reducer,在项目中我们通常会使用combineReducers组合成一个大的reducer传入,那combineReducers做了什么呢?
combineReducers
1 | function combineReducers(reducers) { |
combineReducers接收一个对象,里面的key是每一个小reducer文件或函数导出的namespace,value则是与其对应的reducer函数实体。然后它会将这些不同的reducer函数合并到一个reducer函数中。它会调用每一个合并的子reducer,并且会将他们的结果放入一个state中,最后返回一个闭包使我们可以像操作之前的子reducer一样操作这个大reducer。对于我们开发者来说只要注意导入的子reducer文件名,即key值便可。
preloadedState就是我们传入的初始state,当然源码中的注释里描述还可以向服务端渲染中的应用注入该值or恢复历史用户的session记录,不过没实践过,就不延展了…
最后的入参enhancer比较关键,字面理解就是用来增强功能的,先看看部分源码:
1 | if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') { |
在这里我们发现其实createStore可以只接收2个参数,当第二个参数为函数时,会自动初始化state为undefined,所以看到一些createStore只传了2个参数不要觉得奇怪。
applyMiddleware
关于applyMiddleware,是一个组合中间件的API,社区中也有诸多辅助的库如redux-logger(派发action时,在控制台打印)、redux-thunk(支持function类型的action)、redux-saga(采用Generator语法的异步流程处理方式,避免了callback hell)等等。
下面我们先看看源码,再看看通常是如何使用的。
1 | function compose(...funcs) { |
1 | function applyMiddleware(...middlewares) { |
从源码中分析,可以比较直观地理解API意图,如redux中的工具方法compose是为了优雅地进行高阶函数嵌套;假设我们有高阶函数A、B、C ,要实现A(B(C(…args)))的效果,如果没有compose,就需要不断地将返回结果赋值,调用。而使用compose,只需要一次赋值let HOC = compose(A, B, C);,然后调用HOC(...args)即可。
而applyMiddleware的作用也很自然得到是用来增强我们生成的store对象的dispatch方法,比如增加识别function类型的action、支持Generator写法,输出日志等等。
前文源码中的middlewareAPI内的属性初见者可能会比较迷,不过我们结合一下redux-thunk的源码就很好理解了:
1 | function createThunkMiddleware(extraArgument) { |
通过代码,我们可以得知一般middleWare的内部构造都遵从一个({ getState, dispatch }) => next => action => {...}的范式,并且导出的时候已经被调用了一次,即返回了一个需要接收getState和dispatch的函数。这样就很好解释middlewareAPI的数据结构了。综合applyMiddleware调用易得其中的next方法即我们传入的store.dispatch,通过这般应用中间件的方式支持function类型的action派发。
bindActionCreators
这个方法本质上就是一个帮我们将action直接进行store.dispatch包裹,方便我们直接进行调用。其实将dispatch注入后再按照我们自定义逻辑去做也完全可以,看个人喜好~
下面看看这部分源码中做了哪些处理:
1 | // 返回一个函数,内部帮我们进行dispatch调用 |
根据官方提供的示例,这个API主要应用在将包裹的多个actionCreator传入子组件中方便调用:
1 | // TodoActionCreators.js |
当然如果只是想对单一的action封装并且不涉及往子组件传方法,后文react-redux中提供的方式会更为简便。
React Redux
前文中讲解了redux的比较关键的一些API,同时也提到了redux仅是构建store的一步,我们还需要有一座桥梁将其与我们的应用连接,那就是react-redux。官方提供了清晰的使用DEMO,核心是一个提供全局store的Provider组件及一个关联store的state内容到组件的connectAPI:
Provider
1 | import React from 'react' |
connect()
1 | import { connect } from 'react-redux' |
可以看到Provider组件是嵌套在我们应用最外层的,这样的结构要让全局组件去获取其中的属性很自然能够联想到React的context,从源码中分析,新版本react-redux已经使用HOOKS语法重构了,不过原理是一样的,ReactReduxContext即通过React.createContext(null)导出的初始context,useMemo用以构造两个监听store变化触发更新的值,contextValue及previousState。useEffect在两值发生变动时进行事件订阅,如果状态改动会通知嵌套的关联子组件。最终是返回一个Context.Provider组件,将contextValue交给嵌套的消费者使用。
1 | import React, { useMemo, useEffect } from 'react' |
connect()涉及到的源码内容比较复杂,这里就不作过深讨论,简单来说就是通过HOC的方式将store的state内容映射到我们的组件props属性上。
前文内容了解得差不多了后,下面说说我个人使用过的一些方式。
目录组织
一般我个人习惯下图这样组织redux的内容结构,因为store是C位,action和reducer都是辅助:
拆分合并reducer
根据业务场景进行对应文件reducer的合并(combineReducers),connect中通过state.xxx.xxx绑定。
connect传参风格
connect的入参有多种处理方式,得到的效果也不同(主要是是否根据绑定内容rerender),我们需要结合自身场景决定哪种使用:
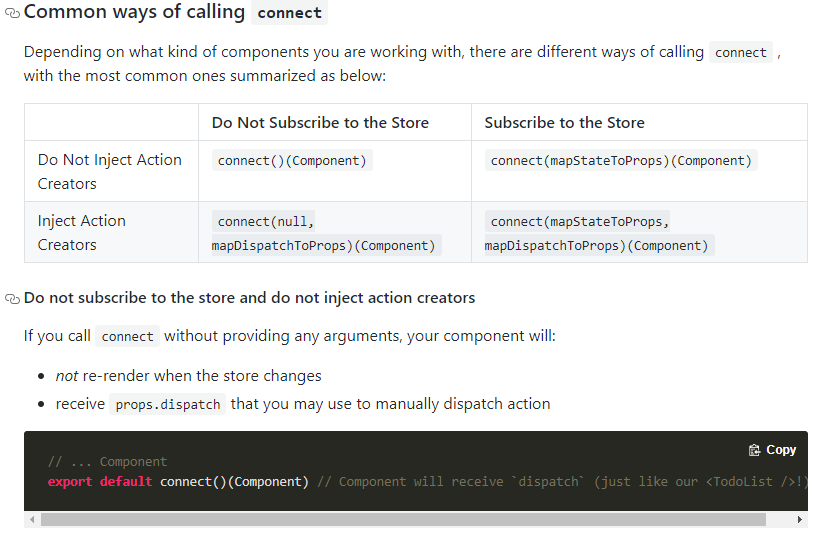
另外官方推荐在mapDispatchToProps中采用传对象的简写格式(dispatch => bindActionCreators({ xxx }, dispatch)的简写)。这些处理都可以通过this.props.xxx直接进行dispatch。当然在不传mapDispatchToProps的情况下,也会为你默认绑定一个dispatch方法到props上,交由开发者手动处理。

PS,connect也可以使用装饰器的写法。
异步历程
架构图