
状态跳变这个问题相信不少做过控制设备页面的前端同学都会遇到,导致这个现象的原因很多,比如由于网络问题造成的回包慢于预期,在界面状态切换后返回了之前的状态对应的回包;又比如海外AWS的IOT云服务有一个delta计算逻辑,在每次控制指令下发后存在多包订阅下发的情况。这些对于前端的状态同步干扰都是非常大的…
背景
每一款上线的单品在多轮测试及UAT体验过程中都出现了跳变现象。由于历史问题,所有单品采用一套sdk逻辑,而这个逻辑在上线的单品中已经使用了一年多,且最初的维护人员均已离职。所以是否修改就成了一个风险比较大的问题,往往最后的结果就变成了让步释放。
然而情况到了最近发生了改变,由于组织架构调整,我目前负责了海外大部分的单品维护和新单品的开发工作。海外又是一个比较注重体验和赚钱的BU,这个跳变问题基本就变成了一个必解的问题。近期也进行了一些多端的技术方案讨论,发现在我们React-Native端的数据接收处理上有不少可以优化的地方,下面进行复盘。
复盘
现阶段的状态同步做法
前端人员做的基本就是将状态投射到视图上的工作,而在IoT的业务场景基本都是由大量的控制单元组成,它们都遵从一个状态管理的逻辑。我们可以简化成一个控制单元(比如一个控制“开关”的按钮)来分析。
当用户在页面上的进行按钮点击时,为了保证用户的实时感知反馈,此时的按钮状态肯定取决于用户的点击动作。然而这个按钮控制对应了实际的IoT设备状态,我们又应当以设备真实的状态作为依赖。于是我们目前有下面的状态:
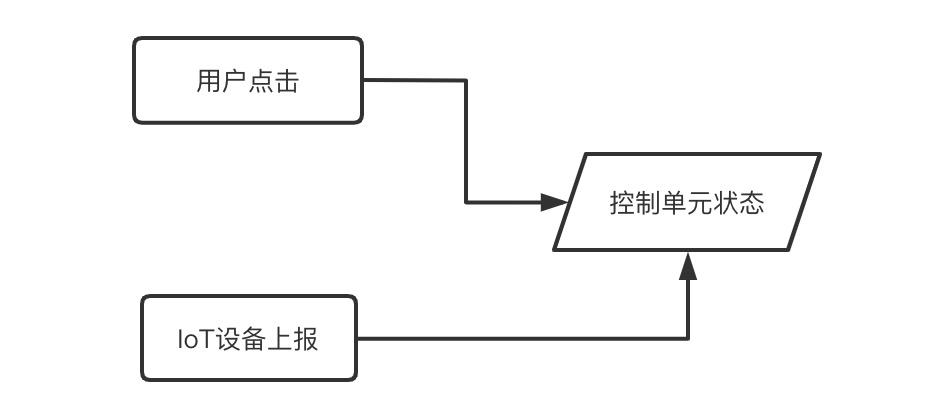
这里就出现了一个同步问题:如何在我们先遵循用户的本意改变界面状态后再次同步成真实的设备响应态?
过去在web开发中,以上这个问题似乎都不会成为一个纠结的问题。因为在一个ajax请求场景中,我们可以很容易地通过请求状态和响应码进行loading态的过度,最终根据结果同步状态。
但是在当前IoT业务场景中,由于采取MQTT协议,整体是一个发布订阅的模式,也就没有回调这个时机去做以上的事情,并且我们还需要在第一时间遵从用户的控制感知,不能有什么loading的过度状态,否则整个控制体验是非常糟糕的。
于是在过去的sdk中,采取了一个期望值管理的方案。它本质上是一个Map结构的定时器,会对用户操作下发指令进行收集,并在下一个mqtt broker服务器传过来消息的时机进行逻辑处理,重新保证我们页面渲染状态的真实性。
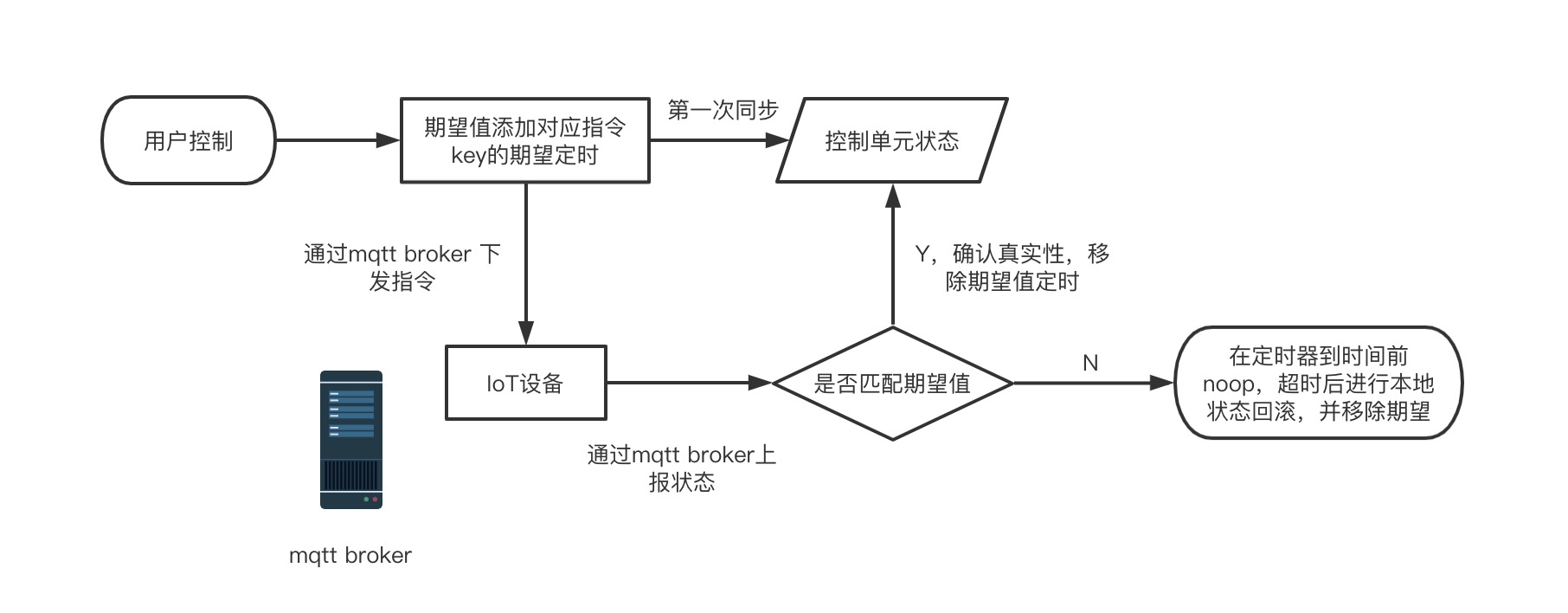
这样就处理了数据真实同步的问题,但同时也为之后的很多状态跳变问题引出了伏笔。
为什么会状态跳变
在对这个历史sdk代码阅读后,结合了目前用户、测试提出的问题,大致能够得到三种可能导致跳变现象的原因,这里直接进行总结:
- 网络链路问题导致的丢包(主要表现在mqtt broker到app端的下发包丢失),在测试使用国内网络测试海外项目时,比较容易出现。
- 海外AWS的IOT云服务的多包下发 ➕ 用户频繁切换控制状态导致期望值无法正常命中,偶现。
- 网络问题导致的竞态问题,即前包在后包后返回,期望值无法正常工作,暂未遇见。
- 忽视了JS单线程与Event Loop的执行顺序,在添加期望值管理器前先同步修改了界面状态,在会定时上报状态的设备中比较容易出现。
以上总结中2,4问题为主因,1为次因,3为潜在风险。
对策
找到了原因,问题逐个击破就不难了。
对于第一点,在RN端可以调整的逻辑就是在期望值超时未返回时,重新主动进行aws云的影子信息拉取,可以保证数据准确的同时不发生跳变。因为本质上之前的逻辑在超时会直接回滚过去的状态,这也意味着当发生这种超时未收到回包场景,必然引发跳变。当然本地状态回滚这个逻辑并不会直接移除,而是作为这个主动拉取失败后的backup。
PS,这个方案的改进依据是app下发到云的控制指令,及固件上报给云的状态均是正常到达的,云端影子也更新为最新状态,但是云传回给app的消息丢包。即根因为mqtt协议通道不稳定,但是通过http请求直接拉取可以在变相再次确认数据准确的同时规避回滚跳变的体验问题。
对于第二点,过去的期望值管理,实际上在用户频繁切换状态时,每一次对同一控制指令key切换,期望值都会被置换为新的,所以即便频繁切换,只要确保顺序回包,那些老包不匹配的都会被屏蔽掉。之所以还会跳变的根因在于海外AWS的多回包现象,比如用户在一个控制指令的A、B两个状态间切换,先从A->B,再从B->A。那对于实际场景的回包就类似:
1 | // A A B |
我们发现每次控制指令下发只有最后一条是真实的,前面的那多余的包在我们这种场景下就会影响期望值的工作,因为此时用户的期望已经变成A了,一旦回包不够快,那么第一个控制指令前面的A就会命中现在的期望值,导致后续的频繁跳变。
所以我们需要过滤出真实的固件上报数据:结合AWS的回包可知,当回包current下的数据结构reported和desired内容全等时,就是真实上报值,那么我们实现一个简单的全等比较函数isEqual进行数据过滤即可。
对于第三点,经典的竞态问题,web上也很常见,我们采取比较常见的做法,通过一个自增的属性判断。可以是时间戳也可以是一些id之类的,这里我们使用aws返回数据结构内的version,讨论后发现这个也符合自增规律,可以用来规避竞态问题。
最后一点,在reducer中同步改变当前页面依赖的store状态前,大意地将设置期望值并下发指令这一步处理成了异步(本是同步)。
可以说是没有注意细节导致的,因为原本是为了进行debounce处理,然而sdk已经做了这一步,所以将外层的防抖去除即可,下面还原下当时的代码(伪):
1 | export function changeSomeMode(data) { |
在这个场景下我们就会得到实际发生的执行逻辑: 修改界面状态 -> 收到设备的状态上报,同步界面状态(可能在这个时机插入) -> 添加期望 -> 下发控制指令 -> 收到设备响应后重新上报的状态 -> 重新同步状态。
很明显,这就是我们出现跳变的直接原因。
在之前我的《Event-Loop一次盘清楚》一文中对相关执行顺序也进行了比较详细的分析,所以这里我们其实只要保证添加期望在修改界面状态这一步前同步完成即可。
因为我们状态同步的回调函数会在macroTask中等我们同步调用栈跑完之后才会执行,故确保了正确的响应顺序,简单修改如下:
1 | export function changeSomeMode(data) { |
小结
以上就是基于旧版本sdk进行优化的三个方向及策略,当然在业务层也要注意Event Loop潜在带来的执行时序问题,目前编码也已完成,在开发环境部署测试后也不再出现跳变现象,整体表现良好。
经过这次问题定位和处理,可以发现设计一个比较完善的数据流转逻辑要考虑的因素是非常多的,前期的基建没做好,往往后期基于此衍生搭建的产品都会受到挑战。
所以千里之行,始于足下,一个鲁棒性强的系统设计至关重要💻
加油提升自己的技术和业务水平吧!
共勉🎉。